Recent Posts

Add Interactions to Regularized Regression
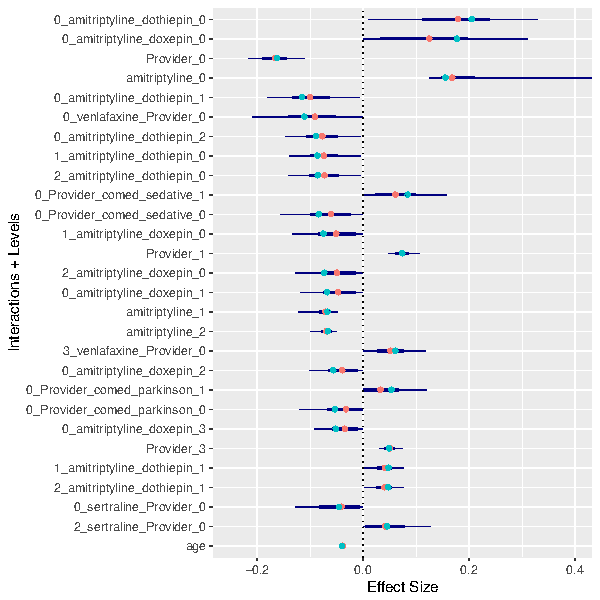
Lasso & glinternet Every Data Scientist and her dog know linear and logistic regression. The majority will probably also know that these models have regularized versions, which increase predictive performance by reducing variance (at the cost of a small increase in bias). Choosing L1-regularization (Lasso) even gets you variable selection for free. The theory behind these models is covered expertly in The Elements of Statistical Learning (for an easier version, see An Introduction to Statistical Learning), and implemented nicely in the packages glmnet for R and scikitlearn for Python.

Big Networks in Healthcare
See also the MJA podcast episode accompanying this article.
Our joint work (UNSW CBDRH and Statistics) which analyses Australian patient claim data using big network algorithms is now available on the MJA website. We have processed MBS claims data of 10% of Australians over the years 1994-2014, trying to shed light on the following research questions:
What is the patient sharing behaviour of general practitioners (GPs): are there any meaningful clusters (called “Provider Practice Communities, PPC”) of GPs which collaborate and share patients?

NUS-MIT Datathon
Last week I had the privilege to participate in the NUS-NUH-MIT DATATHON and Workshop on applications of AI in healthcare with the UNSW Centre for Big Data Research in Health (CBDRH) team (Tim Churches, Mark Hanly, Oisin Fitzgerald and Oluwadamisola Sotade).
Thu & Fri: Workshop & Talks In the workshop “Deploying AI Solutions in Real Clinical Practices” by Dr Ngiam Kee Yuan (CTO, NUHS) we discussed
The large NUHS (National University Health System) databases and their storage structure Data security and ownership Applications for access to data The always changing standards of diagnosis codes (ICD9, ICD10, SNOMED, …) and the problem of matching doctors diagnoses to these codes.

PhD internship in Machine Learning
In the internship, you’ll explore the latest machine learning methods such as tree ensemble methods, graphical models and neural networks and compare their performance to what is the current industry standard. A great opportunity to improve your machine learning skills and create valuable insights for the credit risk industry.
Applications close 20 June, 2018.
Apply here: https://aprintern.org.au/2018/05/21/int-0431/
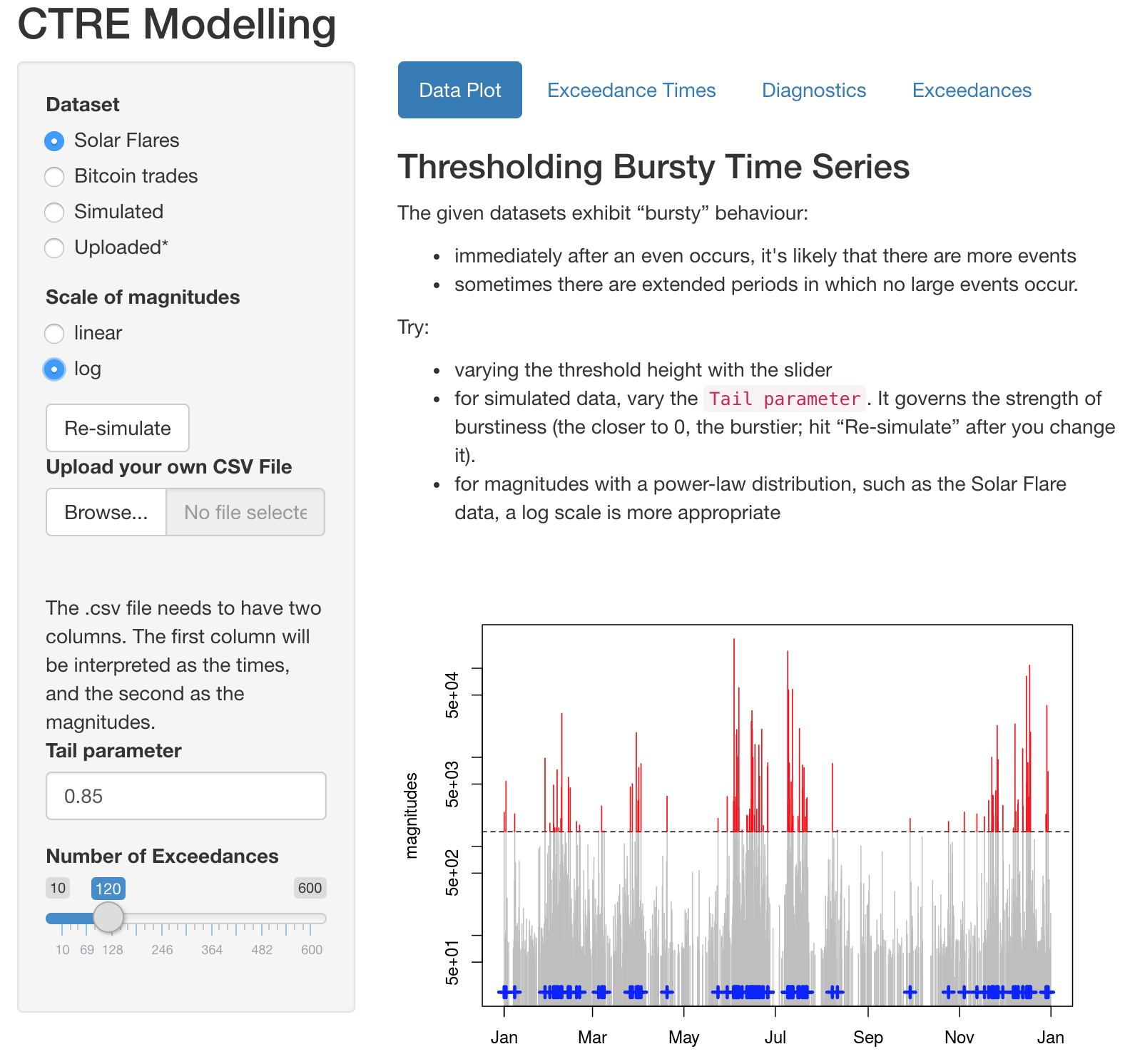
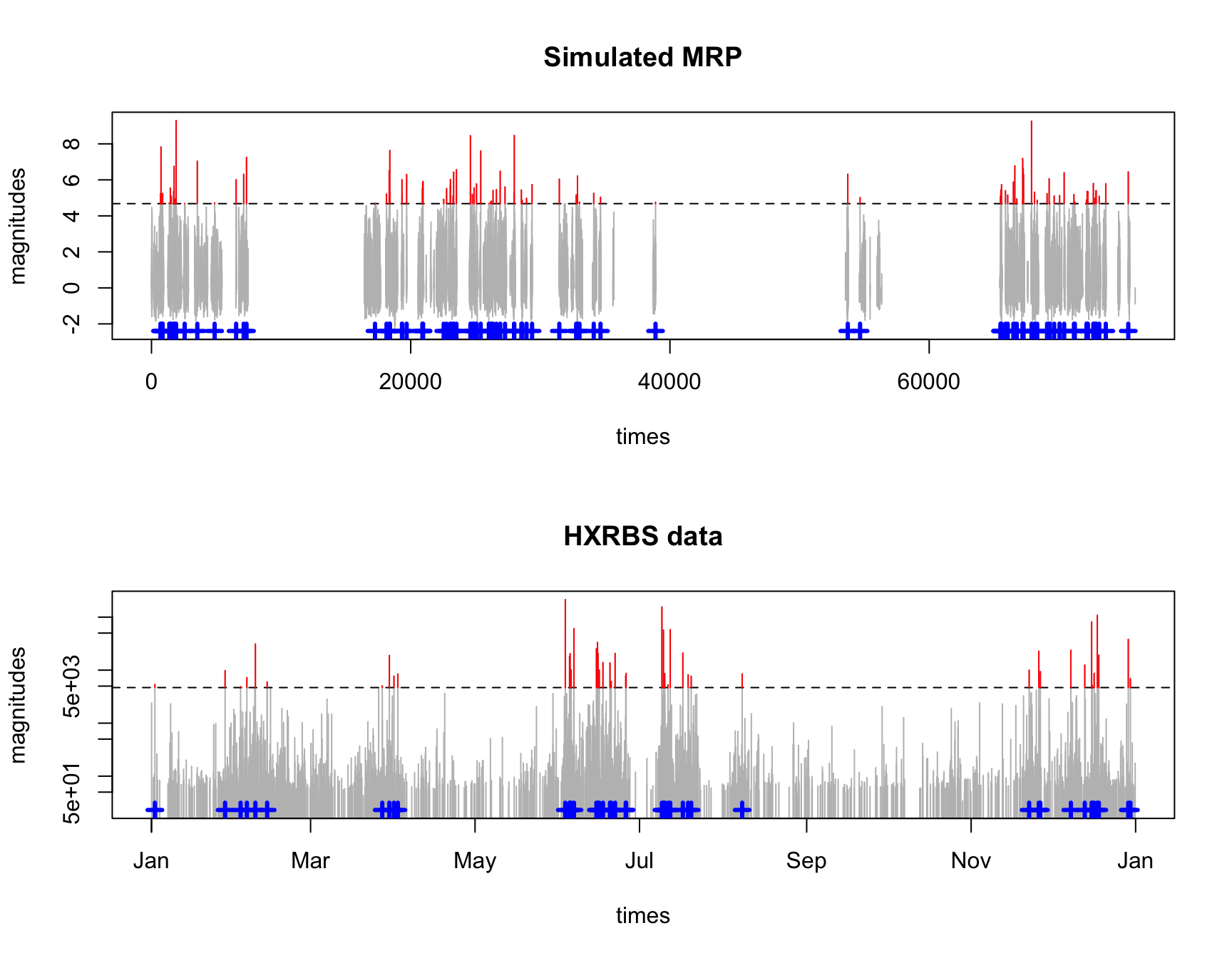
R package CTRE: thresholding bursty time series
The R package is now available on CRAN. It Models extremes of ‘bursty’ time series via Continuous Time Random Exceedances (CTRE). (See companion paper.)